[Python] 텍스트 유사도(2)_XGboost
텍스트 유사도 (2)
- 캐글 ‘Quora question pairs dataset’으로 중복/ 유사도 검사
텐서플로2와 머신러닝으로 시작하는 자연어처리 p230- 캐글 api 사용해서 불러와도 되지만, 구글 로그인으로 접속해서 다운받아서 진행했다.
- 데이터 전처리 - 학습, 평가 데이터 분리, 모델링(
XGboost), 예측 순서로 진행
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
%matplotlib inline
train_data = pd.read_csv('C:/Users/silan/Python/quora-question-pairs/train.csv/'+'train.csv')
train_data.head()
| id | qid1 | qid2 | question1 | question2 | is_duplicate | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | What is the step by step guide to invest in sh... | What is the step by step guide to invest in sh... | 0 |
| 1 | 1 | 3 | 4 | What is the story of Kohinoor (Koh-i-Noor) Dia... | What would happen if the Indian government sto... | 0 |
| 2 | 2 | 5 | 6 | How can I increase the speed of my internet co... | How can Internet speed be increased by hacking... | 0 |
| 3 | 3 | 7 | 8 | Why am I mentally very lonely? How can I solve... | Find the remainder when [math]23^{24}[/math] i... | 0 |
| 4 | 4 | 9 | 10 | Which one dissolve in water quikly sugar, salt... | Which fish would survive in salt water? | 0 |
print('파일의 크기: ')
for file in os.listdir('C:/Users/silan/Python/quora-question-pairs/'):
if 'csv' in file and 'zip' not in file:
print(file.ljust(30) + str(round(os.path.getsize('C:/Users/silan/Python/quora-question-pairs/'+file)/1000000, 2)) + 'MB')
파일의 크기:
test.csv 314.02MB
train.csv 0.0MB
print('전체 학습 데이터의 개수 {}'.format(len(train_data)))
전체 학습 데이터의 개수 404290
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 404290 entries, 0 to 404289
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 404290 non-null int64
1 qid1 404290 non-null int64
2 qid2 404290 non-null int64
3 question1 404289 non-null object
4 question2 404288 non-null object
5 is_duplicate 404290 non-null int64
dtypes: int64(4), object(2)
memory usage: 18.5+ MB
# 중복 여부 파악
train_set = pd.Series(train_data['question1'].tolist() +
train_data['question2'].tolist()).astype(str)
train_set.head()
0 What is the step by step guide to invest in sh...
1 What is the story of Kohinoor (Koh-i-Noor) Dia...
2 How can I increase the speed of my internet co...
3 Why am I mentally very lonely? How can I solve...
4 Which one dissolve in water quikly sugar, salt...
dtype: object
print('학습 데이터 전체 수: {}'.format(len(np.unique(train_set))))
print('반복되는 질문 수: {}'.format(np.sum(train_set.value_counts() > 1))) # 2개 이상인 것
학습 데이터 전체 수: 537361
반복되는 질문 수: 111873
시각화: 이상치 및 중복질문 개수 확인
- figsize (가로, 세로)
- bins : 히스토그램에서 버킷 범위
- range: x 값의 범위
- alpha: 그래프 색상 투명도
- color: 색상
- label: 축 레이블
# plt.figure(figsize=(20, 10))
# plt.hist(train_set.value_counts(), bins=50, )
# plt.yscale('log', nonposy='clip')
# histogram on linear scale
# plt.subplot(211)
# hist, bins, _ = plt.hist(train_set.value_counts(), bins=50)
# histogram on log scale.
# Use non-equal bin sizes, such that they look equal on log scale.
logbins = np.logspace(np.log10(bins[0]),np.log10(bins[-1]),len(bins))
plt.subplot(212)
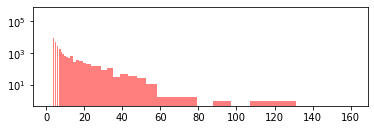
plt.hist(train_set.value_counts(), bins=logbins, alpha=0.5, color='r', label='word')
plt.yscale('log')
# plt.title('Log-histogram of Questions appearance counts')
# plt.xlabel('# of ocurrences of question')
# plt.ylabel('# of questions')
plt.show()
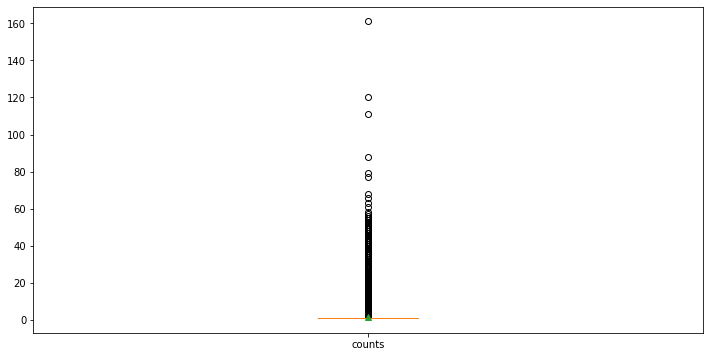
plt.figure(figsize=(12,6))
plt.boxplot([train_set.value_counts()], labels=['counts'], showmeans=True)
{'whiskers': [<matplotlib.lines.Line2D at 0x248130dd2b0>,
<matplotlib.lines.Line2D at 0x248130dd580>],
'caps': [<matplotlib.lines.Line2D at 0x248130dd910>,
<matplotlib.lines.Line2D at 0x248130ddb20>],
'boxes': [<matplotlib.lines.Line2D at 0x248130d6fa0>],
'medians': [<matplotlib.lines.Line2D at 0x248130dddf0>],
'fliers': [<matplotlib.lines.Line2D at 0x248130e43d0>],
'means': [<matplotlib.lines.Line2D at 0x248130e4100>]}
전처리: 라벨 개수 균형 맞추기
- 중복/중복이 아닌 데이터 중 중복 데이터가 훨씬 많아서
- 데이터 개수를 줄인 후 분석 진행
import re
import json
train_pos_data = train_data.loc[train_data['is_duplicate'] == 1]
train_neg_data = train_data.loc[train_data['is_duplicate'] == 0]
class_difference = len(train_neg_data) - len(train_pos_data)
sample_frac = 1- (class_difference / len(train_neg_data))
train_neg_data = train_neg_data.sample(frac = sample_frac) # 샘플링
print(f'중복 질문 개수: {len(train_pos_data)}')
print(f'중복이 아닌 질문 개수: {len(train_neg_data)}')
중복 질문 개수: 149263
중복이 아닌 질문 개수: 149263
train_data = pd.concat([train_neg_data, train_pos_data])
train_data.head()
| id | qid1 | qid2 | question1 | question2 | is_duplicate | |
|---|---|---|---|---|---|---|
| 187868 | 187868 | 286229 | 79093 | What is the corporate culture like at Demandwa... | What is the corporate culture like at Quantum?... | 0 |
| 184405 | 184405 | 281752 | 281753 | How do I fix a location unavailable error in t... | Does the Android Device Manager app use the in... | 0 |
| 370455 | 370455 | 501024 | 501025 | What are some things new employees should know... | What are some things new employees should know... | 0 |
| 332792 | 332792 | 366013 | 306645 | Can I get pregnant 2 days after ovulation? | Can you get pregnant a day after ovulation? | 0 |
| 130994 | 130994 | 210113 | 210114 | How is characterization used in "The Great Gat... | How is carelessness portrayed in "The Great Ga... | 0 |
change_filter = re.compile('[a-z]+')
q1 = [str(s) for s in train_data['question1']]
q2 = [str(s) for s in train_data['question2']]
filtered_q1 = list()
filtered_q2 = list()
for q in q1:
filtered_q1.append(re.sub(change_filter,"", q).lower())
for q in q2:
filtered_q2.append(re.sub(change_filter,"", q).lower())
전체 단어 사전 만들기
!pip install tensorflow
Collecting tensorflow
Downloading tensorflow-2.10.0-cp39-cp39-win_amd64.whl (455.9 MB)
Collecting tensorflow-io-gcs-filesystem>=0.23.1
Downloading tensorflow_io_gcs_filesystem-0.27.0-cp39-cp39-win_amd64.whl (1.5 MB)
Collecting astunparse>=1.6.0
Using cached astunparse-1.6.3-py2.py3-none-any.whl (12 kB)
Requirement already satisfied: numpy>=1.20 in c:\anaconda\lib\site-packages (from tensorflow) (1.21.5)
Requirement already satisfied: h5py>=2.9.0 in c:\anaconda\lib\site-packages (from tensorflow) (3.6.0)
Requirement already satisfied: packaging in c:\anaconda\lib\site-packages (from tensorflow) (21.3)
Collecting keras-preprocessing>=1.1.1
Using cached Keras_Preprocessing-1.1.2-py2.py3-none-any.whl (42 kB)
Collecting opt-einsum>=2.3.2
Using cached opt_einsum-3.3.0-py3-none-any.whl (65 kB)
Collecting libclang>=13.0.0
Downloading libclang-14.0.6-py2.py3-none-win_amd64.whl (14.2 MB)
Collecting gast<=0.4.0,>=0.2.1
Using cached gast-0.4.0-py3-none-any.whl (9.8 kB)
Collecting tensorboard<2.11,>=2.10
Downloading tensorboard-2.10.1-py3-none-any.whl (5.9 MB)
Requirement already satisfied: wrapt>=1.11.0 in c:\anaconda\lib\site-packages (from tensorflow) (1.12.1)
Requirement already satisfied: typing-extensions>=3.6.6 in c:\anaconda\lib\site-packages (from tensorflow) (4.1.1)
Collecting google-pasta>=0.1.1
Using cached google_pasta-0.2.0-py3-none-any.whl (57 kB)
Requirement already satisfied: six>=1.12.0 in c:\anaconda\lib\site-packages (from tensorflow) (1.16.0)
Collecting flatbuffers>=2.0
Downloading flatbuffers-22.9.24-py2.py3-none-any.whl (26 kB)
Requirement already satisfied: protobuf<3.20,>=3.9.2 in c:\anaconda\lib\site-packages (from tensorflow) (3.19.1)
Collecting termcolor>=1.1.0
Downloading termcolor-2.0.1-py3-none-any.whl (5.4 kB)
Collecting tensorflow-estimator<2.11,>=2.10.0
Downloading tensorflow_estimator-2.10.0-py2.py3-none-any.whl (438 kB)
Requirement already satisfied: setuptools in c:\anaconda\lib\site-packages (from tensorflow) (61.2.0)
Requirement already satisfied: grpcio<2.0,>=1.24.3 in c:\anaconda\lib\site-packages (from tensorflow) (1.42.0)
Collecting absl-py>=1.0.0
Downloading absl_py-1.2.0-py3-none-any.whl (123 kB)
Collecting keras<2.11,>=2.10.0
Downloading keras-2.10.0-py2.py3-none-any.whl (1.7 MB)
Requirement already satisfied: wheel<1.0,>=0.23.0 in c:\anaconda\lib\site-packages (from astunparse>=1.6.0->tensorflow) (0.37.1)
Requirement already satisfied: google-auth<3,>=1.6.3 in c:\anaconda\lib\site-packages (from tensorboard<2.11,>=2.10->tensorflow) (1.33.0)
Collecting tensorboard-data-server<0.7.0,>=0.6.0
Using cached tensorboard_data_server-0.6.1-py3-none-any.whl (2.4 kB)
Collecting tensorboard-plugin-wit>=1.6.0
Using cached tensorboard_plugin_wit-1.8.1-py3-none-any.whl (781 kB)
Requirement already satisfied: werkzeug>=1.0.1 in c:\anaconda\lib\site-packages (from tensorboard<2.11,>=2.10->tensorflow) (2.0.3)
Requirement already satisfied: markdown>=2.6.8 in c:\anaconda\lib\site-packages (from tensorboard<2.11,>=2.10->tensorflow) (3.3.4)
Requirement already satisfied: requests<3,>=2.21.0 in c:\anaconda\lib\site-packages (from tensorboard<2.11,>=2.10->tensorflow) (2.27.1)
Collecting google-auth-oauthlib<0.5,>=0.4.1
Using cached google_auth_oauthlib-0.4.6-py2.py3-none-any.whl (18 kB)
Requirement already satisfied: cachetools<5.0,>=2.0.0 in c:\anaconda\lib\site-packages (from google-auth<3,>=1.6.3->tensorboard<2.11,>=2.10->tensorflow) (4.2.2)
Requirement already satisfied: pyasn1-modules>=0.2.1 in c:\anaconda\lib\site-packages (from google-auth<3,>=1.6.3->tensorboard<2.11,>=2.10->tensorflow) (0.2.8)
Requirement already satisfied: rsa<5,>=3.1.4 in c:\anaconda\lib\site-packages (from google-auth<3,>=1.6.3->tensorboard<2.11,>=2.10->tensorflow) (4.7.2)
Collecting requests-oauthlib>=0.7.0
Using cached requests_oauthlib-1.3.1-py2.py3-none-any.whl (23 kB)
Requirement already satisfied: pyasn1<0.5.0,>=0.4.6 in c:\anaconda\lib\site-packages (from pyasn1-modules>=0.2.1->google-auth<3,>=1.6.3->tensorboard<2.11,>=2.10->tensorflow) (0.4.8)
Requirement already satisfied: idna<4,>=2.5 in c:\anaconda\lib\site-packages (from requests<3,>=2.21.0->tensorboard<2.11,>=2.10->tensorflow) (2.10)
Requirement already satisfied: certifi>=2017.4.17 in c:\anaconda\lib\site-packages (from requests<3,>=2.21.0->tensorboard<2.11,>=2.10->tensorflow) (2021.10.8)
Requirement already satisfied: charset-normalizer~=2.0.0 in c:\anaconda\lib\site-packages (from requests<3,>=2.21.0->tensorboard<2.11,>=2.10->tensorflow) (2.0.4)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in c:\anaconda\lib\site-packages (from requests<3,>=2.21.0->tensorboard<2.11,>=2.10->tensorflow) (1.26.9)
Collecting oauthlib>=3.0.0
Downloading oauthlib-3.2.1-py3-none-any.whl (151 kB)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in c:\anaconda\lib\site-packages (from packaging->tensorflow) (3.0.4)
Installing collected packages: oauthlib, requests-oauthlib, tensorboard-plugin-wit, tensorboard-data-server, google-auth-oauthlib, absl-py, termcolor, tensorflow-io-gcs-filesystem, tensorflow-estimator, tensorboard, opt-einsum, libclang, keras-preprocessing, keras, google-pasta, gast, flatbuffers, astunparse, tensorflow
Successfully installed absl-py-1.2.0 astunparse-1.6.3 flatbuffers-22.9.24 gast-0.4.0 google-auth-oauthlib-0.4.6 google-pasta-0.2.0 keras-2.10.0 keras-preprocessing-1.1.2 libclang-14.0.6 oauthlib-3.2.1 opt-einsum-3.3.0 requests-oauthlib-1.3.1 tensorboard-2.10.1 tensorboard-data-server-0.6.1 tensorboard-plugin-wit-1.8.1 tensorflow-2.10.0 tensorflow-estimator-2.10.0 tensorflow-io-gcs-filesystem-0.27.0 termcolor-2.0.1
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(filtered_q1 + filtered_q2)
question1_sequence = tokenizer.texts_to_sequences(filtered_q1)
question2_sequence = tokenizer.texts_to_sequences(filtered_q2)
#길이 맞추기
MAX_SEQUENCE_LENGTH = 31 # 평균길이로 설정, 변경 가능
q1_data = pad_sequences(question1_sequence, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
q2_data = pad_sequences(question2_sequence, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
# 단어사전, 라벨 값 확인
word_vocab = {}
word_vocab = tokenizer.word_index
word_vocab["<PAD>"] = 0
labels = np.array(train_data['is_duplicate'],dtype=int)
print(f'Shape of question1 data: {q1_data.shape}')
print(f'Shape of question2 data: {q2_data.shape}')
print(f'Shape of label: {labels.shape}')
print(f'Words of index: {len(word_vocab)}')
Shape of question1 data: (298526, 31)
Shape of question2 data: (298526, 31)
Shape of label: (298526,)
Words of index: 11870
# 전처리 끝난 데이터 저장하기
data_configs = {}
data_configs['vocab'] = word_vocab
data_configs['vocab_size'] = len(word_vocab)
TRAIN_Q1_DATA = 'q1_train.npy'
TRAIN_Q2_DATA = 'q2_train.npy'
TRAIN_LABEL_DATA = 'label_train.npy'
DATA_CONFIGS = 'data_configs.npy'
path = 'C:/Users/silan/Python/quora-question-pairs/'
np.save(open(path + TRAIN_Q1_DATA, 'wb'), q1_data)
np.save(open(path + TRAIN_Q2_DATA, 'wb'), q2_data)
np.save(open(path + TRAIN_LABEL_DATA, 'wb'), labels)
json.dump(data_configs, open(path + DATA_CONFIGS, 'w'))
TEST 데이터 전처리
path = 'C:/Users/silan/Python/quora-question-pairs/'
test_data = pd.read_csv(path +'test.csv', encoding = 'utf-8')
valid_ids = [type(x) == int for x in test_data.test_id]
test_data = test_data[valid_ids].drop_duplicates() # 중복값 제거
change_filter = re.compile('[a-z]+')
q1 = [str(s) for s in test_data['question1']]
q2 = [str(s) for s in test_data['question2']]
filtered_q1 = list()
filtered_q2 = list()
for q in q1:
filtered_q1.append(re.sub(change_filter,"", q).lower())
for q in q2:
filtered_q2.append(re.sub(change_filter,"", q).lower())
# 토큰화
tokenizer = Tokenizer()
tokenizer.fit_on_texts(filtered_q1 + filtered_q2)
test_data_question1_sequence = tokenizer.texts_to_sequences(filtered_q1)
test_data_question2_sequence = tokenizer.texts_to_sequences(filtered_q2)
#길이 맞추기
MAX_SEQUENCE_LENGTH = 31 # 평균길이로 설정, 변경 가능
q1_data = pad_sequences(test_data_question1_sequence, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
q2_data = pad_sequences(test_data_question2_sequence, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
test_ids = np.array(test_data['test_id'])
print(f'Shape of question1 data: {q1_data.shape}')
print(f'Shape of question2 data: {q2_data.shape}')
print(f'Shape of Ids: {test_ids.shape}')
TEST_Q1_DATA = 'q1_test.npy'
TEST_Q2_DATA = 'q2_test.npy'
TEST_ID_DATA = 'test_ids.npy'
path = 'C:/Users/silan/Python/quora-question-pairs/'
np.save(open(path + TEST_Q1_DATA, 'wb'), q1_data)
np.save(open(path + TEST_Q2_DATA, 'wb'), q2_data)
np.save(open(path + TEST_ID_DATA, 'wb'), test_ids)
Shape of question1 data: (2345796, 31)
Shape of question2 data: (2345796, 31)
Shape of Ids: (2345796,)
모델링 (XGboost)
- 앙상블 부스팅(boosting) 기법 사용
- 앙상블?
- 여러 개의 학습 모델을 통해 각각의 결과를 예측하고 (결과값의 평균) 모든 결과를 동등하게 얻는
배깅과 달리 부스팅은 각 결과를 순차적으로 취합하며, 학습 후 잘못 예측한 부분에 가중치를 줘서 다시 학습하는 방식
- XG부스트: 트리 부스팅 방식+ 경사하강법 (Gradient Descent) + 병렬처리 사용하여 시간 단축할 수 있는 모델
# 저장한 전처리 파일 불러와서 질문 쌍으로 만들기
train_q1_data = np.load(open(path+ TRAIN_Q1_DATA, 'rb'))
train_q2_data = np.load(open(path+ TRAIN_Q2_DATA, 'rb'))
train_labels = np.load(open(path+ TRAIN_LABEL_DATA, 'rb'))
train_input = np.stack((train_q1_data, train_q2_data), axis=1) # [[A], [B]] 형태
print(train_input)
[[[ 1 7 3 ... 0 0 0]
[ 1 16 3 ... 0 0 0]]
[[ 3 2 5 ... 0 0 0]
[ 7 5 7 ... 0 0 0]]
[[ 1 6 18 ... 0 0 0]
[ 1 12 18 ... 0 0 0]]
...
[[ 3 0 0 ... 0 0 0]
[ 3 0 0 ... 0 0 0]]
[[ 1 19 0 ... 0 0 0]
[ 1 19 13 ... 0 0 0]]
[[ 7 0 0 ... 0 0 0]
[ 2 0 0 ... 0 0 0]]]
print(train_input.shape)
(298526, 2, 31)
다양한 포맷 데이터를 XGboost DMatrix로 변환하기
- https://xgboost.readthedocs.io/en/stable/python/python_intro.html
!pip install xgboost
Collecting xgboost
Downloading xgboost-1.6.2-py3-none-win_amd64.whl (125.4 MB)
Requirement already satisfied: scipy in c:\anaconda\lib\site-packages (from xgboost) (1.7.3)
Requirement already satisfied: numpy in c:\anaconda\lib\site-packages (from xgboost) (1.21.5)
Installing collected packages: xgboost
Successfully installed xgboost-1.6.2
train_labels.shape
(298526,)
train_input.shape
(298526, 2, 31)
from sklearn.model_selection import train_test_split
train_input, eval_input, train_label, eval_label = train_test_split(train_input,
train_labels,
test_size=0.2,
random_state=4242)
# random_state 값은 추출 데이터 고정, 값은 임의로 지정가능
# sum 함수로 2개의 질문을 1개로 만들어준다.
import xgboost as xgb
train_data = xgb.DMatrix(train_input.sum(axis=1), label=train_label)
eval_data = xgb.DMatrix(eval_input.sum(axis=1), label=eval_label)
data_list = [(train_data, 'train'), (eval_data, 'valid')]
data_list
[(<xgboost.core.DMatrix at 0x24893cb18b0>, 'train'),
(<xgboost.core.DMatrix at 0x24893cb1d30>, 'valid')]
파라미터 설정
1) 목적함수: 이진 로지스틱 함수
2) 평가지표: Root Means Squared error
3) 학습 반복 횟수: num_boost_round=1000
4) 에러 값이 줄지 않는 동안 N번째 학습 조기 종료가능:early_stopping_rounds
params = {}
params['objective'] = 'binary:logistic'
params['eval_metric'] = 'rmse'
params
{'objective': 'binary:logistic', 'eval_metric': 'rmse'}
num_round = 1000
bst = xgb.train(params, train_data, num_round)
preds = bst.predict(eval_data)
bst
<xgboost.core.Booster at 0x24893b25c40>
bst = xgb.train(params, train_data, num_boost_round = 1000, evals=data_list,
early_stopping_rounds = 10)
[0] train-rmse:0.49072 valid-rmse:0.49080
[1] train-rmse:0.48529 valid-rmse:0.48549
[2] train-rmse:0.48186 valid-rmse:0.48230
[3] train-rmse:0.47984 valid-rmse:0.48041
[4] train-rmse:0.47780 valid-rmse:0.47833
[5] train-rmse:0.47673 valid-rmse:0.47735
[6] train-rmse:0.47604 valid-rmse:0.47670
[7] train-rmse:0.47493 valid-rmse:0.47567
[8] train-rmse:0.47463 valid-rmse:0.47547
[9] train-rmse:0.47358 valid-rmse:0.47457
[10] train-rmse:0.47309 valid-rmse:0.47415
[11] train-rmse:0.47263 valid-rmse:0.47375
[12] train-rmse:0.47196 valid-rmse:0.47315
[13] train-rmse:0.47177 valid-rmse:0.47300
[14] train-rmse:0.47109 valid-rmse:0.47240
[15] train-rmse:0.47095 valid-rmse:0.47230
[16] train-rmse:0.47052 valid-rmse:0.47191
[17] train-rmse:0.47039 valid-rmse:0.47181
[18] train-rmse:0.47024 valid-rmse:0.47169
[19] train-rmse:0.46963 valid-rmse:0.47117
[20] train-rmse:0.46926 valid-rmse:0.47086
[21] train-rmse:0.46850 valid-rmse:0.47021
[22] train-rmse:0.46839 valid-rmse:0.47014
[23] train-rmse:0.46757 valid-rmse:0.46937
[24] train-rmse:0.46753 valid-rmse:0.46934
[25] train-rmse:0.46746 valid-rmse:0.46933
[26] train-rmse:0.46706 valid-rmse:0.46898
[27] train-rmse:0.46699 valid-rmse:0.46895
[28] train-rmse:0.46671 valid-rmse:0.46873
[29] train-rmse:0.46663 valid-rmse:0.46869
[30] train-rmse:0.46655 valid-rmse:0.46868
[31] train-rmse:0.46635 valid-rmse:0.46859
[32] train-rmse:0.46599 valid-rmse:0.46833
[33] train-rmse:0.46592 valid-rmse:0.46828
[34] train-rmse:0.46579 valid-rmse:0.46821
[35] train-rmse:0.46577 valid-rmse:0.46821
[36] train-rmse:0.46526 valid-rmse:0.46780
[37] train-rmse:0.46485 valid-rmse:0.46747
[38] train-rmse:0.46480 valid-rmse:0.46744
[39] train-rmse:0.46443 valid-rmse:0.46714
[40] train-rmse:0.46439 valid-rmse:0.46713
[41] train-rmse:0.46436 valid-rmse:0.46713
[42] train-rmse:0.46417 valid-rmse:0.46702
[43] train-rmse:0.46393 valid-rmse:0.46687
[44] train-rmse:0.46367 valid-rmse:0.46669
[45] train-rmse:0.46364 valid-rmse:0.46667
[46] train-rmse:0.46338 valid-rmse:0.46652
[47] train-rmse:0.46331 valid-rmse:0.46649
[48] train-rmse:0.46329 valid-rmse:0.46648
[49] train-rmse:0.46311 valid-rmse:0.46638
[50] train-rmse:0.46309 valid-rmse:0.46638
[51] train-rmse:0.46308 valid-rmse:0.46637
[52] train-rmse:0.46275 valid-rmse:0.46614
[53] train-rmse:0.46271 valid-rmse:0.46611
[54] train-rmse:0.46265 valid-rmse:0.46610
[55] train-rmse:0.46249 valid-rmse:0.46605
[56] train-rmse:0.46228 valid-rmse:0.46592
[57] train-rmse:0.46221 valid-rmse:0.46590
[58] train-rmse:0.46219 valid-rmse:0.46591
[59] train-rmse:0.46188 valid-rmse:0.46564
[60] train-rmse:0.46154 valid-rmse:0.46545
[61] train-rmse:0.46135 valid-rmse:0.46534
[62] train-rmse:0.46092 valid-rmse:0.46494
[63] train-rmse:0.46091 valid-rmse:0.46493
[64] train-rmse:0.46090 valid-rmse:0.46493
[65] train-rmse:0.46088 valid-rmse:0.46492
[66] train-rmse:0.46086 valid-rmse:0.46490
[67] train-rmse:0.46082 valid-rmse:0.46488
[68] train-rmse:0.46073 valid-rmse:0.46480
[69] train-rmse:0.46068 valid-rmse:0.46478
[70] train-rmse:0.46064 valid-rmse:0.46477
[71] train-rmse:0.46037 valid-rmse:0.46460
[72] train-rmse:0.46023 valid-rmse:0.46457
[73] train-rmse:0.46012 valid-rmse:0.46454
[74] train-rmse:0.46001 valid-rmse:0.46448
[75] train-rmse:0.46000 valid-rmse:0.46448
[76] train-rmse:0.45999 valid-rmse:0.46447
[77] train-rmse:0.45996 valid-rmse:0.46447
[78] train-rmse:0.45989 valid-rmse:0.46439
[79] train-rmse:0.45988 valid-rmse:0.46439
[80] train-rmse:0.45975 valid-rmse:0.46434
[81] train-rmse:0.45940 valid-rmse:0.46406
[82] train-rmse:0.45906 valid-rmse:0.46383
[83] train-rmse:0.45877 valid-rmse:0.46361
[84] train-rmse:0.45874 valid-rmse:0.46360
[85] train-rmse:0.45870 valid-rmse:0.46357
[86] train-rmse:0.45852 valid-rmse:0.46348
[87] train-rmse:0.45834 valid-rmse:0.46341
[88] train-rmse:0.45805 valid-rmse:0.46319
[89] train-rmse:0.45795 valid-rmse:0.46318
[90] train-rmse:0.45791 valid-rmse:0.46318
[91] train-rmse:0.45790 valid-rmse:0.46318
[92] train-rmse:0.45771 valid-rmse:0.46305
[93] train-rmse:0.45749 valid-rmse:0.46290
[94] train-rmse:0.45732 valid-rmse:0.46281
[95] train-rmse:0.45710 valid-rmse:0.46269
[96] train-rmse:0.45696 valid-rmse:0.46262
[97] train-rmse:0.45694 valid-rmse:0.46261
[98] train-rmse:0.45687 valid-rmse:0.46261
[99] train-rmse:0.45684 valid-rmse:0.46261
[100] train-rmse:0.45683 valid-rmse:0.46260
[101] train-rmse:0.45668 valid-rmse:0.46251
[102] train-rmse:0.45666 valid-rmse:0.46251
[103] train-rmse:0.45659 valid-rmse:0.46248
[104] train-rmse:0.45649 valid-rmse:0.46244
[105] train-rmse:0.45635 valid-rmse:0.46237
[106] train-rmse:0.45615 valid-rmse:0.46228
[107] train-rmse:0.45606 valid-rmse:0.46227
[108] train-rmse:0.45594 valid-rmse:0.46222
[109] train-rmse:0.45587 valid-rmse:0.46221
[110] train-rmse:0.45584 valid-rmse:0.46221
[111] train-rmse:0.45574 valid-rmse:0.46218
[112] train-rmse:0.45556 valid-rmse:0.46211
[113] train-rmse:0.45545 valid-rmse:0.46206
[114] train-rmse:0.45531 valid-rmse:0.46202
[115] train-rmse:0.45512 valid-rmse:0.46189
[116] train-rmse:0.45503 valid-rmse:0.46189
[117] train-rmse:0.45498 valid-rmse:0.46190
[118] train-rmse:0.45484 valid-rmse:0.46180
[119] train-rmse:0.45476 valid-rmse:0.46177
[120] train-rmse:0.45475 valid-rmse:0.46177
[121] train-rmse:0.45467 valid-rmse:0.46173
[122] train-rmse:0.45466 valid-rmse:0.46172
[123] train-rmse:0.45462 valid-rmse:0.46171
[124] train-rmse:0.45445 valid-rmse:0.46163
[125] train-rmse:0.45444 valid-rmse:0.46163
[126] train-rmse:0.45442 valid-rmse:0.46163
[127] train-rmse:0.45436 valid-rmse:0.46161
[128] train-rmse:0.45433 valid-rmse:0.46161
[129] train-rmse:0.45431 valid-rmse:0.46160
[130] train-rmse:0.45425 valid-rmse:0.46159
[131] train-rmse:0.45419 valid-rmse:0.46159
[132] train-rmse:0.45417 valid-rmse:0.46159
[133] train-rmse:0.45416 valid-rmse:0.46158
[134] train-rmse:0.45415 valid-rmse:0.46158
[135] train-rmse:0.45415 valid-rmse:0.46158
[136] train-rmse:0.45414 valid-rmse:0.46158
[137] train-rmse:0.45414 valid-rmse:0.46158
[138] train-rmse:0.45409 valid-rmse:0.46158
[139] train-rmse:0.45408 valid-rmse:0.46157
[140] train-rmse:0.45405 valid-rmse:0.46156
[141] train-rmse:0.45390 valid-rmse:0.46149
[142] train-rmse:0.45389 valid-rmse:0.46149
[143] train-rmse:0.45370 valid-rmse:0.46135
[144] train-rmse:0.45356 valid-rmse:0.46125
[145] train-rmse:0.45346 valid-rmse:0.46119
[146] train-rmse:0.45334 valid-rmse:0.46112
[147] train-rmse:0.45314 valid-rmse:0.46102
[148] train-rmse:0.45314 valid-rmse:0.46102
[149] train-rmse:0.45305 valid-rmse:0.46102
[150] train-rmse:0.45293 valid-rmse:0.46098
[151] train-rmse:0.45278 valid-rmse:0.46092
[152] train-rmse:0.45270 valid-rmse:0.46091
[153] train-rmse:0.45267 valid-rmse:0.46091
[154] train-rmse:0.45265 valid-rmse:0.46091
[155] train-rmse:0.45260 valid-rmse:0.46090
[156] train-rmse:0.45253 valid-rmse:0.46087
[157] train-rmse:0.45238 valid-rmse:0.46081
[158] train-rmse:0.45232 valid-rmse:0.46078
[159] train-rmse:0.45215 valid-rmse:0.46070
[160] train-rmse:0.45213 valid-rmse:0.46069
[161] train-rmse:0.45193 valid-rmse:0.46056
[162] train-rmse:0.45174 valid-rmse:0.46051
[163] train-rmse:0.45164 valid-rmse:0.46047
[164] train-rmse:0.45155 valid-rmse:0.46046
[165] train-rmse:0.45152 valid-rmse:0.46045
[166] train-rmse:0.45150 valid-rmse:0.46044
[167] train-rmse:0.45150 valid-rmse:0.46044
[168] train-rmse:0.45148 valid-rmse:0.46044
[169] train-rmse:0.45145 valid-rmse:0.46043
[170] train-rmse:0.45135 valid-rmse:0.46038
[171] train-rmse:0.45124 valid-rmse:0.46034
[172] train-rmse:0.45113 valid-rmse:0.46024
[173] train-rmse:0.45102 valid-rmse:0.46017
[174] train-rmse:0.45098 valid-rmse:0.46016
[175] train-rmse:0.45086 valid-rmse:0.46009
[176] train-rmse:0.45084 valid-rmse:0.46009
[177] train-rmse:0.45073 valid-rmse:0.46006
[178] train-rmse:0.45069 valid-rmse:0.46006
[179] train-rmse:0.45065 valid-rmse:0.46004
[180] train-rmse:0.45062 valid-rmse:0.46004
[181] train-rmse:0.45061 valid-rmse:0.46004
[182] train-rmse:0.45058 valid-rmse:0.46004
[183] train-rmse:0.45057 valid-rmse:0.46003
[184] train-rmse:0.45046 valid-rmse:0.45996
[185] train-rmse:0.45037 valid-rmse:0.45991
[186] train-rmse:0.45031 valid-rmse:0.45991
[187] train-rmse:0.45028 valid-rmse:0.45990
[188] train-rmse:0.45027 valid-rmse:0.45990
[189] train-rmse:0.45027 valid-rmse:0.45989
[190] train-rmse:0.45026 valid-rmse:0.45989
[191] train-rmse:0.45019 valid-rmse:0.45989
[192] train-rmse:0.45012 valid-rmse:0.45988
[193] train-rmse:0.45011 valid-rmse:0.45987
[194] train-rmse:0.45009 valid-rmse:0.45988
[195] train-rmse:0.45009 valid-rmse:0.45988
[196] train-rmse:0.45009 valid-rmse:0.45988
[197] train-rmse:0.44999 valid-rmse:0.45985
[198] train-rmse:0.44998 valid-rmse:0.45983
[199] train-rmse:0.44996 valid-rmse:0.45983
[200] train-rmse:0.44985 valid-rmse:0.45975
[201] train-rmse:0.44977 valid-rmse:0.45972
[202] train-rmse:0.44971 valid-rmse:0.45969
[203] train-rmse:0.44969 valid-rmse:0.45969
[204] train-rmse:0.44953 valid-rmse:0.45962
[205] train-rmse:0.44941 valid-rmse:0.45957
[206] train-rmse:0.44927 valid-rmse:0.45953
[207] train-rmse:0.44927 valid-rmse:0.45953
[208] train-rmse:0.44926 valid-rmse:0.45953
[209] train-rmse:0.44919 valid-rmse:0.45952
[210] train-rmse:0.44914 valid-rmse:0.45951
[211] train-rmse:0.44912 valid-rmse:0.45950
[212] train-rmse:0.44897 valid-rmse:0.45939
[213] train-rmse:0.44892 valid-rmse:0.45938
[214] train-rmse:0.44891 valid-rmse:0.45938
[215] train-rmse:0.44891 valid-rmse:0.45938
[216] train-rmse:0.44889 valid-rmse:0.45937
[217] train-rmse:0.44884 valid-rmse:0.45937
[218] train-rmse:0.44883 valid-rmse:0.45938
[219] train-rmse:0.44882 valid-rmse:0.45937
[220] train-rmse:0.44877 valid-rmse:0.45936
[221] train-rmse:0.44872 valid-rmse:0.45934
[222] train-rmse:0.44872 valid-rmse:0.45934
[223] train-rmse:0.44871 valid-rmse:0.45934
[224] train-rmse:0.44866 valid-rmse:0.45933
[225] train-rmse:0.44866 valid-rmse:0.45933
[226] train-rmse:0.44866 valid-rmse:0.45933
[227] train-rmse:0.44866 valid-rmse:0.45932
[228] train-rmse:0.44865 valid-rmse:0.45933
[229] train-rmse:0.44865 valid-rmse:0.45932
[230] train-rmse:0.44862 valid-rmse:0.45932
[231] train-rmse:0.44861 valid-rmse:0.45932
[232] train-rmse:0.44861 valid-rmse:0.45931
[233] train-rmse:0.44860 valid-rmse:0.45931
[234] train-rmse:0.44858 valid-rmse:0.45930
[235] train-rmse:0.44853 valid-rmse:0.45929
[236] train-rmse:0.44850 valid-rmse:0.45929
[237] train-rmse:0.44850 valid-rmse:0.45929
[238] train-rmse:0.44850 valid-rmse:0.45930
[239] train-rmse:0.44848 valid-rmse:0.45929
[240] train-rmse:0.44846 valid-rmse:0.45929
[241] train-rmse:0.44842 valid-rmse:0.45929
[242] train-rmse:0.44833 valid-rmse:0.45926
[243] train-rmse:0.44831 valid-rmse:0.45927
[244] train-rmse:0.44830 valid-rmse:0.45926
[245] train-rmse:0.44830 valid-rmse:0.45926
[246] train-rmse:0.44818 valid-rmse:0.45918
[247] train-rmse:0.44814 valid-rmse:0.45918
[248] train-rmse:0.44814 valid-rmse:0.45917
[249] train-rmse:0.44813 valid-rmse:0.45917
[250] train-rmse:0.44812 valid-rmse:0.45917
[251] train-rmse:0.44812 valid-rmse:0.45917
[252] train-rmse:0.44808 valid-rmse:0.45918
[253] train-rmse:0.44807 valid-rmse:0.45918
[254] train-rmse:0.44805 valid-rmse:0.45918
[255] train-rmse:0.44803 valid-rmse:0.45917
[256] train-rmse:0.44803 valid-rmse:0.45917
[257] train-rmse:0.44797 valid-rmse:0.45916
[258] train-rmse:0.44792 valid-rmse:0.45917
[259] train-rmse:0.44791 valid-rmse:0.45917
[260] train-rmse:0.44790 valid-rmse:0.45916
[261] train-rmse:0.44789 valid-rmse:0.45916
[262] train-rmse:0.44787 valid-rmse:0.45914
[263] train-rmse:0.44785 valid-rmse:0.45913
[264] train-rmse:0.44785 valid-rmse:0.45913
[265] train-rmse:0.44783 valid-rmse:0.45912
[266] train-rmse:0.44773 valid-rmse:0.45909
[267] train-rmse:0.44764 valid-rmse:0.45906
[268] train-rmse:0.44754 valid-rmse:0.45901
[269] train-rmse:0.44743 valid-rmse:0.45899
[270] train-rmse:0.44737 valid-rmse:0.45899
[271] train-rmse:0.44728 valid-rmse:0.45896
[272] train-rmse:0.44727 valid-rmse:0.45896
[273] train-rmse:0.44725 valid-rmse:0.45896
[274] train-rmse:0.44723 valid-rmse:0.45896
[275] train-rmse:0.44723 valid-rmse:0.45896
[276] train-rmse:0.44720 valid-rmse:0.45896
[277] train-rmse:0.44720 valid-rmse:0.45895
[278] train-rmse:0.44713 valid-rmse:0.45894
[279] train-rmse:0.44713 valid-rmse:0.45893
[280] train-rmse:0.44701 valid-rmse:0.45888
[281] train-rmse:0.44696 valid-rmse:0.45885
[282] train-rmse:0.44689 valid-rmse:0.45884
[283] train-rmse:0.44681 valid-rmse:0.45884
[284] train-rmse:0.44675 valid-rmse:0.45883
[285] train-rmse:0.44671 valid-rmse:0.45882
[286] train-rmse:0.44656 valid-rmse:0.45877
[287] train-rmse:0.44652 valid-rmse:0.45877
[288] train-rmse:0.44644 valid-rmse:0.45876
[289] train-rmse:0.44643 valid-rmse:0.45876
[290] train-rmse:0.44628 valid-rmse:0.45872
[291] train-rmse:0.44618 valid-rmse:0.45867
[292] train-rmse:0.44609 valid-rmse:0.45865
[293] train-rmse:0.44603 valid-rmse:0.45863
[294] train-rmse:0.44588 valid-rmse:0.45853
[295] train-rmse:0.44582 valid-rmse:0.45849
[296] train-rmse:0.44575 valid-rmse:0.45846
[297] train-rmse:0.44572 valid-rmse:0.45846
[298] train-rmse:0.44563 valid-rmse:0.45842
[299] train-rmse:0.44557 valid-rmse:0.45840
[300] train-rmse:0.44551 valid-rmse:0.45839
[301] train-rmse:0.44551 valid-rmse:0.45839
[302] train-rmse:0.44549 valid-rmse:0.45838
[303] train-rmse:0.44543 valid-rmse:0.45837
[304] train-rmse:0.44539 valid-rmse:0.45835
[305] train-rmse:0.44536 valid-rmse:0.45835
[306] train-rmse:0.44530 valid-rmse:0.45833
[307] train-rmse:0.44525 valid-rmse:0.45831
[308] train-rmse:0.44515 valid-rmse:0.45827
[309] train-rmse:0.44512 valid-rmse:0.45826
[310] train-rmse:0.44512 valid-rmse:0.45826
[311] train-rmse:0.44493 valid-rmse:0.45811
[312] train-rmse:0.44485 valid-rmse:0.45808
[313] train-rmse:0.44474 valid-rmse:0.45805
[314] train-rmse:0.44463 valid-rmse:0.45802
[315] train-rmse:0.44447 valid-rmse:0.45791
[316] train-rmse:0.44441 valid-rmse:0.45789
[317] train-rmse:0.44436 valid-rmse:0.45789
[318] train-rmse:0.44434 valid-rmse:0.45789
[319] train-rmse:0.44434 valid-rmse:0.45789
[320] train-rmse:0.44433 valid-rmse:0.45789
[321] train-rmse:0.44432 valid-rmse:0.45790
[322] train-rmse:0.44432 valid-rmse:0.45790
[323] train-rmse:0.44425 valid-rmse:0.45789
[324] train-rmse:0.44422 valid-rmse:0.45789
[325] train-rmse:0.44420 valid-rmse:0.45789
[326] train-rmse:0.44419 valid-rmse:0.45789
평가 데이터로 예측하기
TEST_Q1_DATA = 'q1_test.npy'
TEST_Q2_DATA = 'q2_test.npy'
TEST_ID_DATA = 'test_ids.npy'
test_q1_data = np.load(open(path+ TEST_Q1_DATA, 'rb'))
test_q2_data = np.load(open(path+ TEST_Q2_DATA, 'rb'))
test_id_data = np.load(open(path+ TEST_ID_DATA, 'rb'))
test_input = np.stack((test_q1_data, test_q2_data), axis=1) # [[A], [B]] 형태
test_data = xgb.DMatrix(test_input.sum(axis=1))
test_predict = bst.predict(test_data)
# 새로운 저장 경로 만들고 싶을 때
# if not os.path.exists(path):
# os.makedirs()
# 결과 저장
output = pd.DataFrame({'test_id': test_id_data, 'is_duplicate': test_predict})
output.to_csv(path + 'simple_xgb.csv', index=False)
output.head(3)
| test_id | is_duplicate | |
|---|---|---|
| 0 | 0 | 0.211880 |
| 1 | 1 | 0.109923 |
| 2 | 2 | 0.399594 |
output['is_duplicate'].max()
0.9999127388000488
output['is_duplicate'].value_counts()
0.603274 211672
0.567154 81359
0.605096 46305
0.609642 42195
0.404560 37942
...
0.356317 1
0.519661 1
0.556234 1
0.219877 1
0.235535 1
Name: is_duplicate, Length: 491424, dtype: int64
댓글남기기